> GitHub PRs are Markdown documents, and some organizations have specific templates with checklists for all reviewers to complete. Enforcing these often requires ugly regexes that are a pain to write and worse to debug
This is because GitHub is not building the features we need, instead they are putting their energy towards the AI land grab. Bitbucket, by contrast, has a feature where you can block PRs using a checkbox list outside of the description box. There are better ways to solve this first example from OP readme. Cool project, I write mainly MDX these days, would be cool to see support for that dialect
Not only is GitHub focused on AI, but they’re also making their UI slower and jankier by rewriting it in React.
I feel like a “Linear for GitHub” is due.
Is it true that it is React’s fault? Is there any other replacement for heavy user interaction, that is clearly more performative? You cannot do that on server side.
GitHub worked great for 15+ years without React everywhere. I'm finding interacting with issues to be a whole lot jankier over the past few months.
IIRC only search is React. Everything else is still Hotwire or Hotwire-like, with numerous bugs
GitHub Issues is React now - I think as of a month or so ago. Try running the React Developer Toolbar on those pages to see.
Whatever is at fault, their code viewer now sucks. I often cannot even use basic text functionality like double click + drag to highlight/select whole words. It has become broken software at some point.
For the code search one annoyance that they introduced was, that one needs to be logged in to search a project. Another annoyance is how the search works. Why, oh why, do soooo many programs/websites/software things have issues searching for a simple 100% substring match? There should always be an option in a search for most software, to search for exact substring without involving any magic. Then the checkbox to optionally ignore case. Only when this basic search functionality is ensured, should they care about developing anything else.
Just selecting text in the code viewer is so broken it drives me nuts everytime. Thankfully you can just press "." to open VS Code Web with the current file open.
Yes, there are lots of better options. React is around the bottom 25th percentile of frameworks when comparing speed. https://krausest.github.io/js-framework-benchmark/2025/table...
In my experience performance issues in React also creep in without it being obvious when developing, especially across a larger team. It tends to be more obvious with server-side frameworks like django or rails.
> Is there any other replacement for heavy user interaction, that is clearly more performative?
Well-written React?
After reading a bunch of stuff as result of this, I think you are the most correct. Difference in performance on different frameworks seems to be more like philosophical rather than practical.
It is enough that your website has just a couple of images, comparison of the "shipping size" of the runtime bundling becomes rather meaningless. It is the same for initial latency for showing the rendered content.
These frameworks were designed for heavy sites, and their "base speed" becomes irrelevant. If you understand how do they work and use them correctly, there shouldn't be that much difference. Assuming, that we use JavaScript on client-side in the end.
How many well-written code bases have you seen?
React is a PITA to learn, and even the easiest frameworks encounter devs who jump right in and commit shot code to deliver "value" right away, only for that code to live on forever haunting the devs left with mess after the founder coders move on.
Vue, Svelte, Solid.
SolidJS
Holy crap, is that why it's felt so syrupy recently? What was wrong with the old implementation?!
It wasn't React. Everyone knows modern applications must be written in React.
As a greybeard sysadmin, this is why I write pure html5/css3 with as little js as possible, and where it can't be avoided, vanilla with no frameworks.
I really have grown to hate most frameworks... (and I don't hate em, but for the devs who push them... it's become the new Java, another bane of linux admins everywhere.)
We are in Hell. Ugh.
Linear itself has a workflow for Github: https://linear.app/docs/github
Linear? That website makes my laptop heat up like nuts.
If also hijacks standard browser shortcuts: I try to open the file menu with alt-f, but instead it (un-) marks the issue as "Favorite".
Fwiw im generally ok with this as long as hotkeys are customizable. Apps should behave like apps, and I like having the full array of shortcuts available
Uh... I have no idea what that was, just that the design is completely counter to any attempt to read it.
Which means, probably not a good replacement workflow for a daily driver.
The Markdown parsing library I'm using supports MDX, so it shouldn't be too difficult to come up with syntax for those components. I haven't done that yet, but mostly because I didn't want to go down that path until I knew there was interest and had a concrete use case or two to inform the query syntax.
If you want to open an enhancement request issue, I'm happy to take a look (PRs also welcome, but not required). If you're not on GitHub, let me know and we can figure out some other way to get the request tracked.
Thanks for taking a look at the project!
I don't write rust and already have an MDX toolbox that fits my needs. Browser, GH, and IDE search / TOC are good enough for me.
I'm currently in a phase of trying to shed tools and added complexity, rather than add them
Fair enough!
GitHub was ignoring users needs long before the AI craze.
It's hard to remember, but as soon as gitlab showed up, GitHub went from a "maybe someday if I make it" site to a "let's just use GitHub for everything" site.
Prior to gitlab ratcheting up the usability, features, and cost effectiveness, I preferred hosted git for 99% of use cases.
Is that why Gitlab doesn't innovate anymore? No point if GitHub just steals the features?
I just started using git, can you give me some advice?
Use it everyday, preferable with a porcelain such as magit in emacs.
Alias commands help.
Run your own git server instead of using one of the big names.
Use git hooks. (https://git-scm.com/book/en/v2/Customizing-Git-Git-Hooks)
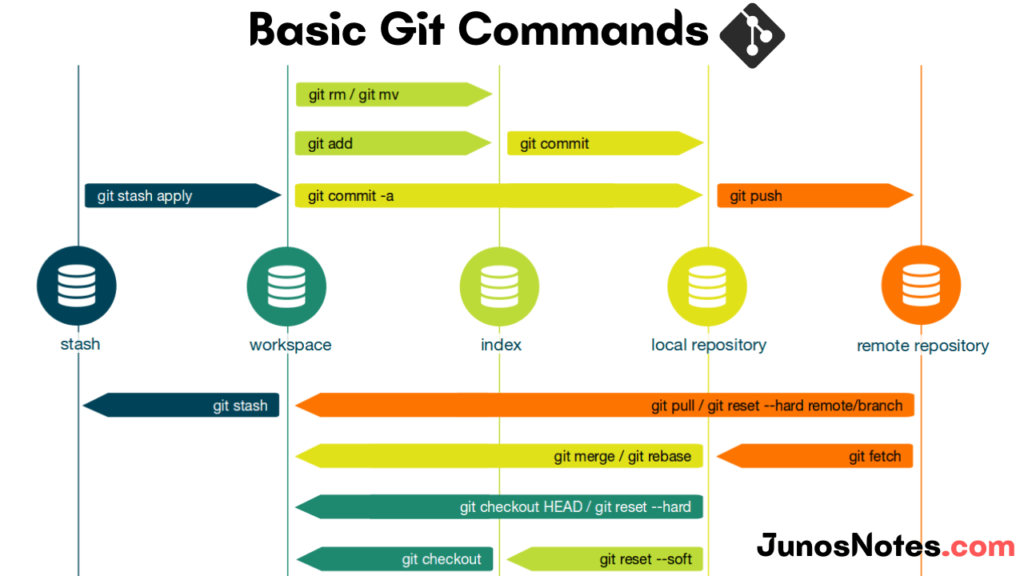
When starting out, looking at visuals of how git works can help a lot I've found when training others. (https://www.junosnotes.com/wp-content/uploads/2021/07/basic-...)
> This is because GitHub is not building the features we need, instead they are putting their energy towards the AI land grab.
You throw the ball to where it's going. Gitlab might be delivering more value in the short term, but if things wind up looking significantly different in ten years, they might be in for a world of hurt. Innovator's dilemma is real.
It's a danger to ignore the tectonic changes happening. It's also incredibly risky to lean fully in, because we're not sure where the value accrues or which systems are the most important to build. It doesn't seem like foundation models are it.
It's smart to build basic scaffolding, let the first movers make all the expensive mistakes, then integrate the winning approaches into your platform. That requires a lot of energy though.
> That requires a lot of energy though.
So do the plagiarism machines!
it's a shame when core feature development seems to lag. i've also been working w/ MDX lately & agree that support would be a great addition.
> Bitbucket, by contrast, has a feature where you can block PRs using a checkbox list outside of the description box
I'm not sure this is better. I like the idea of the full context of the PR being available in a small set of relatively standardised fields. Smaller, non-semantic sets are easier to standardise.
I'm not sure how having a list of remaining tasks that can be added to adhoc and block PRs from merging is not better than check boxes in markdown description box that are little more than aesthetic...
It has saved us from self induced pain and is a great coordination point
Or maybe GitHub built these features over 10 years ago and millions upon millions of people use them daily without issue. You can literally have any semblance of what you're describing with a PR check, and that feature is also pretty old. The API is right there, you just have to use it.
Ironically one of the reasons markdown (and other text based file formats) were popular because you could use regular find/grep to analyze it, and version control to manage it.
I don't think anyone ever really expected to see widespread use of regexes to alter the structure of a Markdown document. Honestly, while something like "look for numbers and surround them with double-asterisks to put them in boldface" is feasible enough (and might even work!), I can't imagine that a lot of people would do that sort of thing very often (or want to) anyway.
If a document is supposed to have structure - even something as simple as nested lists of paragraphs - it doesn't seem realistic to expect regular text manipulation tools to do a whole lot with them. Something like "remove the second paragraph of the third entry in the fourth bullet-point list" is well beyond any sane use of any regex dialect that might be powerful enough. (Keeping in mind that traditional regexes can't balance brackets; presumably they can't properly track indentation levels either.)
See also: TOML - generally quite human-editable, but still very much structured with potentially arbitrary nesting.
> (Keeping in mind that traditional regexes can't balance brackets; presumably they can't properly track indentation levels either.)
You're right: Regular expressions are equivalent to finite state machines[1], which lack the infinite memory needed to handle arbitrarily nested structures [2]. If there is a depth limit, however, it is possible (but painful) to craft a regex to describe the situation. For example, suppose you have a language where angle brackets serve as grouping symbols, like parentheses usually do elsewhere [3]. Ignoring other characters, you could verify balanced brackets up to one nesting level with
/^(<>)*$/
/^(<(<[^<>]*>|[^<>])*>)*$/
---
[1] https://reindeereffect.github.io/2018/06/24/index.html
[2] As do any machines I can afford, but my money can buy a pretty good illusion.
[3] < and > are not among the typical regex metacharacters, so they make for an easier discussion.
I think that prospect (of programmatically structurally editing markdown files) would have made everyone burst out in laughter in 2000; if you want to programmatically alter stuff, put it into sexp's or some other syntax. SGML. Apparently human readable but really a tricky format leads to this sort of thing: https://ruudvanasseldonk.com/2023/01/11/the-yaml-document-fr...
> because you could use regular find/grep to analyze it
They were meant to be analyzable in some ways. Count lines, extract headers, maybe sed-replace some words. But being able to operate/analyze over multiline strings was never a strong point of unix tools.
Definitely, but it's neat nonetheless because more and more things are "structured Markdown" these days. Extremely useful for AI reasoning and outputs.
Man if we only had some type of markdown meant for machines to understand, that was specifically designed to handle arbitrary information nesting and tagging our lives would be so much better now.
We could have called it something like extended markdown language or something and use a wicked acronym like eXMaLa for it.
Shame no such technology exists and never did.
My flow is to go through the Pandoc JSON AST and then use Jq. This works for other input formats, too.
I'm curious how ergonomic you find that? I did look at the pandoc JSON initially, and found it fairly awkward to work with. It's a great interchange format, but doesn't seem optimized for either human interaction or scripting. (It's definitely possible to use it for scripting, it just felt cumbersome to me, personally.)
I've never had a need for parsing markdown like this, bit I have to wonder, would it make to go through HTML instead, given that it's what markdown is designed to compile to? At that point, I'd assume there's any number of existing XML tools that work work, and my (maybe naive) assumption is that typical markdown documents would be relatively flat compared to how deeply nested "native" HTML/XML often gets, so it doesn't seem like most queries would require particularly complex XPath to be able to specify.
I did this for a tool that checks relative links in markdown files, e.g. readmes in a repo.
markdown -> xhtml -> sxml -> logic (racket)
Kind of aligned with this is MarkdownDB, providing an SQLite backend to your Markdown files [0]. Cool to see this, I feel the structure of .md files is not always equally respected or regarded as a data serialisation target.
I think you'd benefit of having some more real-world-ish examples in the README, as someone who doesn't intuit what I'd want to use this for.
That's a great idea, thanks! I'll do that tomorrow or so.
As a preview, two specific cases I've seen:
1) In PRs, some companies like to have semi-structured metadata, like a link to a related ticket under a heading "Ticket". In mdq, you could find that using `# Ticket | [](^https://issues.acme.com/)`
2) Many projects ask people who submit bugs to check off whether they've searched for existing bugs. `- [x] I've looked in the bug tracker for existing bugs`
Agreed. At least 5 examples of output shown being used against a standard markdown document.
Please don’t reimplement JQ. That problem is already solved. Instead, just provide a tool that can convert your target syntax into JSON, then it can be piped to JQ for querying.
Cool thanks for sharing! I'll have to check this out. I've wanted something similar.
After trying a bunch of the usual ones, the only "notes system" I've stuck with is just a directory of markdown files that's automatically committed to git on any change using watchexec.
I've wanted to add a little smarts to it so I could use it to track tasks (eg. sort, prune completed, forward uncomplete tasks over to the next day's journal, collect tasks from "projects", etc.) so I started writing some Rust code using markdown-rs. Then, to round-trip markdown with changes, only the javascript version of the library currently supports serializing github flavored markdown. So then I actually dumped the markdown ast to json from rust and picked it up in js to serialize it for a proof of concept. That's about as far as I got so far. But while markdown-rs saves position information, it doesn't save source token information (like, * and - are both list items) so you can't reliably round-trip.
FWIW, the other thing I was hoping to do was treat markdown documents as trees (based on headings) use an xpath kind of language to pull out sections. Anyway, will check out your code, thanks for posting.
Interesting; one thing you may have learned researching existing tools and libraries: many of them serialize markdown to html before running structured extraction/manipulation - even stuff like converting to pdf.
The core assumption here is that Markdown was/is designed to be serializeable to html - this is why a markdown document/AST is mostly not a tree structure, for tree-ish elements such as sub-sections. Instead, it is flat, an array of elements in order of appearance in the document. Apparently this most closely matches the structure of html, at both the block and inline levels. Only Lists and Blockquotes (afair) support nesting.
Ex: h1 -> paragraph -> h2 -> paragraph is not nested, it is an array of four ordered elements.
Anyway, you might throw a task at Cursor or Copilot to see how an equivalent implementation using html fares against your test suite, you may be able to develop more quickly.
Why not MD -> json, then use jq! That would be half a static site generator there!
Thanks for sharing! No immediate use-case for me right now, but good to know something like this exists.
I wanted to point out little nitpicks for the documented shell invocations:
cat example.md | mdq '# usage'
mdq '# usage' < example.md
echo "$ISSUE_TEXT" | mdq -q '- [x] I have searched for existing issues'
mdq -q '- [x] I have searched for existing issues' <<< "$ISSUE_TEXT"
From the linked web-page
A cat written with UUOC might still be preferred for readability reasons, as reading a piped stream left-to-right might be easier to conceptualize.[14] Also, one wrong use of the redirection symbol > instead of < (often adjacent on keyboards) may permanently delete the content of a file, in other words clobbering, and one way to avoid this is to use cat with pipes.
Thanks for sharing this Yuval! Thanks as well for using permissive licenses so I can use this at work.
Curious, which license can't you use at work for a simple shell tool? Considering you're not linking against it, even GPL3 should be okay, right?
Most big employers consider GPL unusable and will only allow Apache, MIT, BSD, and other permissive patent-free licenses.
So they don't let you use grep? Sounds like hell.
Yeah, caution with GPL is understandable if you're shipping it or making it a part of a hosted service. But internal use is not the intention of GPL, so a blanket ban like that would put that shop at a disadvantage, like the other comment said, that basically rules out all kinds of things.
I worked on a project converting word docs to markdown so they could more easily be ingested into an LLM, one issue was that context windows used to be very short, so we would basically split on `\n#` to get sections, but this turns into a whole thing where you have to make guesses about which header level is appropriate to split at, and then you turn each section into a separate chunk in FAISS. Anyways we ended up using HTML instead of MD but theres so much tooling for traversing HTML and not MD. This would have been helpful for that
This is one of those moments where you come across a tool _just_ at the right moment. I have a task for which this will be perfect
I've always wanted a "literate programming" / jupyter-style notebook based on markdown. Maybe this could help make something like that possible.
Emacs org-mode and babel are what I use instead. Very powerful alternative to Jupyter imho, but of course not for everyone.
I have used commit hooks so that non-emacs users could push updates that still get executed to avoid the emacs tie in though, the biggest issue with it I've found.
Thanks! I have to grapple with some markdown across multiple repos and this'll be a helpful tool in the toolchest.
congrats on your tool, will check it out. I have a side question on markdown: cursor messes up markdown generation quite often for me. I think its responses are always in markdown with sections for code and asking it to generate markdown breaks it. So the question: any ideas on how to have cursor generate markdown?
How is it parsing? Just normal string and regex matching or transforming markdown to an intermediate structured language?
For the markdown, I'm using https://github.com/wooorm/markdown-rs, which is a formal parser that produces an AST. For the query language, I have a very simple hand-rolled parser.
What purpose does this serve that grep doesn't?
Love this! One persons opinion - I’d change it to mq - less chars are always better for command
[dead]
[flagged]
{kind=link}