Thanks for the wiki -- I have always been interested in hardware hacking but I have always felt overwhelmed as I didn't know where to start. I believe this kind of resource can greatly help with that, especially the case studies.
However, I can't help but feel that a major part of the content is LLM-generated, or at least LLM-rewritten. It feels off and uninteresting to read, honestly. Is it the case? To support my case, I see that the case study page (https://www.hardbreak.wiki/introduction/case-study-led-to-a-...) has very similar paragraphs next to each other, the second one seemingly being the "genuine" one, and the first one being the LLM-rewritten version.
I'm not against using LLMs to help fix typos or reformulate things, but you should definitely keep some of your style. The LLM that you used (if you used one) made the content super bland, and as a reader, I'm not really incentivized to browse more.
Get a ham radio technician license, and you may develop an intuitive perspective on most electrical engineering concepts.
i.e. the physics lab derivation of the core EE tool set is unnecessary if you understand what the models are describing.
AI is slop in and slop out... and dangerous to students... =3
John Shive's Wave Machines is where every student should start:
> Get a ham radio technician license, and you may develop an intuitive perspective on most electrical engineering concepts.
May. I managed to get one without developing much intuition for most EE concepts, unfortunately.
Were you also completely turned off by the community?
I ask because I got into it about 15+ years ago for the purposes of helping with emergency comms and learning more about electronics, but found the community extremely hostile toward new comers that did not have money to burn on expensive gear. I ended up just giving up on it after a few years after investing in a bunch of Arduino stuff and learned far more about EE than I ever did playing at radio. The concept of the Elmer seemed dead, leaving nobody who wanted to show the new guys the ropes.
From what I understand, maybe that has changed in recent years?
Weirdly, I did take something away from my experience with ham radio; I know an awful lot about the weather and atmosphere now, which has turned into a lasting interest.
Ham radio's decline is more than explainable as a cultural issue.
The culture of every internet forum I've ever visited for it is absolutely deplorable. It seems like each one has a handful of really grouchy old gatekeepers who lie in wait to absolutely dunk on newcomers.
We agree, but I suppose my next question would be why? What happened to turn these guys (or ham radio culture at large) into grouchy old gatekeepers? I'm generalizing, of course, but they were like that when I arrived. I can't imagine the hobby was always like that, especially seeing some of the old literature from the 50's and 60's in the US, which was very encouraging of mentoring and sharing info.
If it's still the same today as it was back when I tried it out, that's a shame, because ham radio is absolutely full of hardware hacking opportunities. Heck, you can make an antenna out of a retractable tape measure.
> What happened to turn these guys (or ham radio culture at large) into grouchy old gatekeepers? I'm generalizing, of course, but they were like that when I arrived.
My bet would be, the Internet. Mailing lists and then discussion boards (and then group IMs) allowed for deeper, topical conversations, with much lower barrier to entry, so everyone left the radio spectrum - everyone except those already used to spending time on it, and not interested in moving on to the new thing.
Amateur radio has always self-policed to a large extent. Mostly to keep the FCC off their backs, and I'm sure the internet has made it worse, but it's always been there.
Lead paint probably
HAHA that got me good
Maybe, but the problem I see with HAM is that no interesting discussion is allowed to happen in the first place. Between the legal rules, cultural rules, and the expectation to avoid niche topics that would bore out 90% of participants, there's hardly anything left to talk about.
The overlap of hams and preppers is pretty large.. Most of those guys are of a particular mindset that only meshes with other like minded individuals.
> Were you also completely turned off by the community?
I was never turned on :). I got my license partly because other people at our local Hackerspace were getting it, and partly because I imagined it'll be useful to have the knowledge and ability to build and legally operate my own radio hardware.
I never got the whole HAM talking over radio thing. Between the legal and cultural restrictions on the topics, and the expectations of not taking up the airwaves too much, I can't see how you could discuss anything interesting or worthwhile this way. It's no surprise that there seems to be nothing going on other than boring and obnoxious rag chewing - interesting conversations aren't allowed to occur in the first place.
I mean, the intersection between "non-commercial", "non-religious", "non-controversial/non-political", and "interesting to any HAM" is... basically just saying hello, weather, trash talk, and self-referential showing off.
Did you mean you don't understand the equations/theory, or are having difficulty applying the concepts to design circuits?
In the first case, install LTSpice (free from Analog Devices), and head here to run down the basics:
https://www.youtube.com/@FesZElectronics/videos
And in the latter, go though common basic designs analyzing how they work:
https://archive.org/details/encyclopediaofelectroniccircuits...
https://archive.org/details/encyclopediaofel02graf
https://archive.org/details/isbn_9780070110779
https://archive.org/details/encyclopediaofel0006graf
Then try your own designs combining properties of several designs. Start with simple blinkers and buzzers at first... Try to avoid Arduino designs until you've done a few 555, transistor, and opamp circuits first. =3
Most of my issues seem to be about power - I have no feel for the relevant math, so even as I remember the basic equations and methods, I never feel certain I'm calculating it right. So in terms of hands-on experience, I pretty much jumped straight from burning through-hole resistors with 12V battery to ignite rocket motors made of PVC and caramel fuel, to Arduinos and RPIs and NodeMCUs -- basically, stuff that comes with an USB port it can draw power from...
Thanks for the links, I'll work through them and hopefully come out with some understanding at the end of this process :).
Note, part of the fun is the forensic analysis to figure out why stuff didn't work the first time... Maybe a LDO Voron 3d printer kit would be a fun project too =3
I mean I'm a dummy who just wanted to listen to ISS static and trucker jargon.
Indeed, we also end up learning about our sun in levels of detail no person should find enthralling... lol =3
At least in the UK you can't if you're a linux user, the software they use to spy on you while taking the test is windows only.
Well first off, the certificate comes with certain guarantees, and they can't give those guarantees if they can't prove you didn't cheat on the test. "spy on you" is absolutely correct, but a bad faith phrasing. That said, I did my AWS test at a test / exam center where there's isolated computers and cameras to validate that there was no cheating.
dangerous to students
It's fatally dangerous to students who ignore it or dismiss it out of hand. That much is already certain.
How so?
Wait and see. You're not paying attention now, but it's not too late to start.
Go to your favorite programming puzzle site and see how you do against the latest models, for instance. If you can beat o1-pro regularly, for instance, then you're right, you have nothing to worry about and can safely disregard it. Same proposition that was offered to John Henry.
Please reformulate your argument, and I will check back tomorrow:
https://www.youtube.com/watch?v=aNSHZG9blQQ
LLMs are rules based search engines with higher dimension vector spaces encoding related topics. There is nothing intelligent about these algorithms, except the trick ones play on oneself interpreting well structured nonsense.
It is stunting kids development, as students often lack the ability to intuitively reason when they are being misled. "How many R's in 'Strawberry'?" is a classic example exposing the underlying pattern recognition failures. =3
I have never understood why the failure to answer the strawberry question has seen as a compelling argument as to the limits of AI. The AIs that suffer from this problem have difficulty counting. That has never been denied. Those AI's also do not see the letters of the words they are processing. Counting the letters in a word is a task that it is quite unsurprising that it fails. I Would say it is more surprising that that they can perform spelling tasks at all. More importantly the models where such weaknesses became apparent are all from the same timeframe where the models advanced so much that those weaknesses were visible only after so many other greater weaknesses had been overcome.
People didn't think that planes flying so high that pilots couldn't breathe exposed a fundamental limitation of flight, just that their success had revealed the next hurdle.
The assertion that an LLM is X and therefore not intelligent is not a useful claim to make without either proof that it is X and proof that X is insufficient. You could say brains are interconnected cells that send pulses at intervals dictated by a combination of the pulses they sense, and there is nothing intelligent about that. The premises must be true and you have to demonstrate that the conclusion follows from those premises. For the record I think your premises are false and your conclusion doesn't follow.
Without a proof you could hypothesise reasons why such a system might not be intelligent and come up with an example of a task that no system that satisfies the premises could accomplish. While that example is unsolved the hypothesis remains unrefuted. What would you suggest as a test that shows a problem that could not be solved by such a machine? It must be solvable by at least one intelligent entity to show that it is solvable by intelligence. It must be undeniable when the problem is solved.
The AIs that suffer from this problem have difficulty counting.
Ok, give me an example of what you would consider reasoning.
Is that like 80% LLM slop? the allusion for failures to improve productivity in competent developers was cited in the initial response.
The Strawberry test exposes one of the many subtle problems LLMs inherently offer in the Tokenization approach.
The clown car of Phds may be able to entertain the venture capital folks for awhile, but eventually a VR girlfriend chat-bot convinces a kid to kill themselves like last year.
Again, cognitive development like ethics development is currently impossible for LLM as they are lacking any form of intelligence (artificial or otherwise.) People have patched directives into the model, but these weights are likely fundamentally statistically insignificant due to cultural sarcasm in the data sets.
Please write your own responses, =3
You suspect my words of being AI generated while at the same time arguing that AI cannot possibly reason.
It seems like you see AI where there is not, this compromises your ability to assess the limitations of AI.
You say that LLMs cannot have any form of intelligence but for some definitions of intelligence it is obvious they do. Existing models are not capable in all areas but they have some abilities. You are asserting that they cannot be intelligent which implies that you have a different definition of intelligence and that LLMs will never satisfy that definition.
What is that definition for intelligence? How would you prove something does not have it?
"What is that definition for intelligence?"
That is a very open-ended detractor question, and is philosophically loaded with taboo violations of human neurology. i.e. It could seriously harm people to hear my opinion on the matter... so I will insist I am a USB connected turnip for now ... =)
"How would you prove something does not have it?"
A Receiver operating characteristic no better than chance, within a truly randomized data set. i.e. a system incapable of knowing how many Rs in Strawberry at the token level... is also inherently incapable of understanding what a Strawberry means in the context of perception (currently not possible for LLM.)
Have a great day =3
>A Receiver operating characteristic no better than chance, within a truly randomized data set. i.e. a system incapable of knowing how many Rs in Strawberry at the token level... is also inherently incapable of understanding what a Strawberry means in the context of perception (currently not possible for LLM.)
This is just your claim, restated. In short it is saying they don't think because they fundamentally can't think.
There is no support as to why this is the case. Any plain assertion that they don't understand is unprovable because you can't measure directly measure understanding.
Please come up with just one measurable property that you can demonstrate is required for intelligence that LLMs fundamentally lack.
We are at a logical impasse... i.e. failure to understand the noted ROC curve is often a metric that matters in ML development, and LLMs are trivially broken at the tokenization layer:
https://en.wikipedia.org/wiki/Receiver_operating_characteris...
Note, introducing a straw-man argument and or bot slop in an unrelated topic is silly. My anecdotal opinion does not really matter on the subject of algorithmic performance standards. yawn... super boring like ML... lol
https://en.wikipedia.org/wiki/File:Yawning_koala_bear_(35893...
Best of luck, =3
(Shrug) If you're retired or independently wealthy, you can afford that attitude. Hopefully one of those describes you.
Otherwise, you're going to spend the rest of your career saying things like, "Well, OK, so the last model couldn't count the number of Rs in 'Strawberry' and the new one can, but..."
Personally, I dislike being wrong. So I don't base arguments on points that have a built-in expiration date, or that are based on a fundamental misunderstanding of whatever I'm talking about.
Every model is deprecated in time if evidenced Science is done well, and hopefully replaced by something more accurate in time. There is no absolute right/correctness unless you are a naive child under 25 cheating on structured homework.
The point was there is nothing intelligent (or AI) about LLMs except the person fooling themselves.
In general, most template libraries already implement the best possible algorithms from the 1960s, and tuned for architecture specific optimizations. Knowing when each finite option is appropriate takes a bit of understanding/study, but does give results far quicker than fitting a statistically salient nonsense answer. Several study datum from senior developers is already available, and it proves LLMs provide zero benefit to people that know what they are doing.
Note, I am driven by having fun, rather than some bizarre irrational competitiveness. Prove your position, or I will assume you are just a silly person or chat bot. =3
I have no position on whether or not CamperBob is a chat-bot, but they are definitely not being silly. Their point, as I take it, is that it's dangerous to look at the state of "AI" as it is today and then ignore the rate of change. To their stated point from above:
> Otherwise, you're going to spend the rest of your career saying things like, "Well, OK, so the last model couldn't count the number of Rs in 'Strawberry' and the new one can, but..."
That's a very important point. I mean, it's not guaranteed that any form of AI is going to advance to the point that it starts taking jobs from people like us, but when you fail to look forward and project a little bit and imagine what they could do with another year of progress... or two years of progress... or 5 years, etc? I posit that that kind of myopia could leave one very under-prepared for the world one lands in.
> The point was there is nothing intelligent (or AI) about LLMs except the person fooling themselves.
Sure. The "AI Effect". Irrelevant. It doesn't matter how the machine can do your job, or whether or not it's "really intelligent". It just matters that if it can create more value, more cheaply, than you or I, we are going to wind up like John Henry. Who, btw, for anybody not familiar with that particular bit of folklore "[won the race against the machine] only to die in victory with a hammer in hand as his heart gave out from stress."
Both you and this chatbot Bob seem to be overly excited by the newfound LLM ability of correctly counting R's in "strawberry".
For many, this is not a very exciting development.
Mind you, we do follow the progress but your argument of "wait and see" is not deserving serious discussion as your stance has turned into faith.
The limitations of tokenization does not stop with LLMs it seems for bob.
Please don't down-vote the kids karma, as for me it is more important people feel comfortable having conversations (especially when they are almost 99% sure I'm a turnip connected to a USB port.) =3
Where do you see anything about "excitement" about anything? Quit making up bullshit strawman arguments and deal with the issue in a realistic way already. Sheesh.
I'm not arguing for any specific outcome mind you. But a refusal to acknowledge "rate of change" effects and to assume that the future will be like today is incredibly short-sighted and myopic.
"rate of change" effects on speculative fiction is meaningless.
Try to remember to be kind, as we are still waiting to see bob's data =3
Speculative fiction is entertaining, but not based in reality...
"they are definitely not being silly", that sounds like something a silly person would say. =)
" I posit that that kind of myopia could leave one very under-prepared for the world one lands in." The numerous study data analysis results says otherwise... Thus, still speculative hype until proven otherwise.
Not worried... initially suckered into it as a kid too... then left the world of ML years later because it was always boring, lame, and slow to change. lol =3
"they are definitely not being silly", that sounds like something a silly person would say. =)
Ya know, it's fine to disagree with something. But hand-wavy, shallow dismissals of what someone has to say, with no willingness to even attempt to engage with the content on a rational basis, is unbecoming.
I can’t help but have the thought that the Joel_McKay in this conversation is itself an LLM having been prompted to flippantly disregard and downplay mentions of a.i., and LLMs specifically.
I’m not saying it is true , but I am saying it made the tone and content of his messages in this thread seem a lot more self-consistent and explainable when I re-read them with that context in mind. :-)
(@Joel_McKay: apologies for downplaying your sapience - human, LLM or otherwise.)
It hasn't said anything intelligent yet, so there is that...
I asked for bobs proof, and was given marketing.
Then provided instructions on how to present facts, and still await the data.
Then immature folks showed up to try to cow people with troll content.
I don't have to prove anything, as the evidence was already collected and reported in peer-reviewed journals. People just prefer to ignore the cited evidence that proves they are full of steaming piles of fictional hype. =3
Proof of what exactly are you asking for?
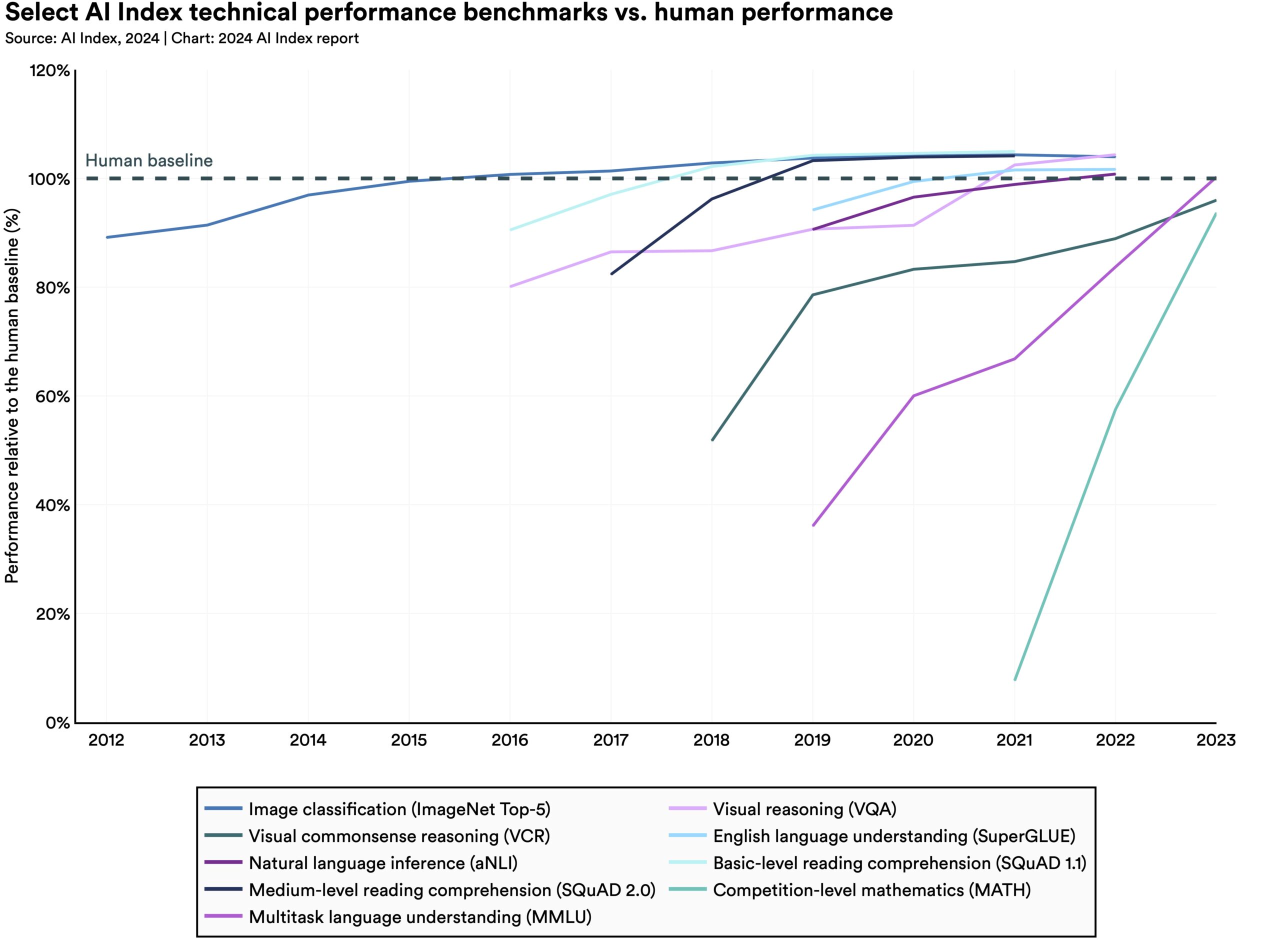
Certainly there is zero question that today's "AI" systems are making progress on a wide array of benchmarks. You can see that here:
https://aiindex.stanford.edu/wp-content/uploads/2024/05/HAI_...
Look in the section starting on page 73. Or just examine this image:
https://aiindex.stanford.edu/wp-content/uploads/2024/04/fig_...
There's your "speculative fiction" you seem so fond of.
Now, if your argument is no more than "who cares about benchmarks, 'AI' still isn't 'Real AI'" then all you're doing is repeating the 'AI Effect'[1] thing over and over again and refusing to acknowledge the obvious reality around you.
The AI's we have today, whether "real AI" or not, are highly capable in many important areas (and yes, far from perfect in others). But there is a starting point to talk about, and yes there is reason to think in terms of "rate of change" unless you have some evidence to support a belief that AI progress has reached a maximum and will progress no further.
I don't have to prove anything, as the evidence was already collected and reported in peer-reviewed journals.
Again, evidence for what exactly? What are you even claiming? All I see Bob claiming, and what I support him(?) in is the idea that there is legit reason to worry about the economic impact of AI in the near('ish?) future.
Indeed, I gather you did not comprehend the threads topics, and instead introduced a straw-man arguing at some point in the future LLM proponents will be less full of steaming piles of fictional hype.
Assertion:
1.) LLMs mislabeled “AI” is dangerous to students due to biasing them with subtle nonsense, and a VR girlfriend convincing a kid to kill themselves. Again the self referential nature of arguing the trends will continue toward AGI is nonscientific reasoning (a.k.a. moving the goal post because the “AI” buzzword lost its meaning due to marketing hype), but this is economically reasonable nonsense rhetoric.
2.) Software developers can be improved or replaced with LLMs. This was proven to be demonstrably false for experienced people.
3.) LLMs are intelligent or will become intelligent. This set of arguments show a fundamental misunderstanding of what LLMs are, and how they function.
4.) Joel may be a USB connected turnip. While I can’t disprove this self presented insight, it may be true at some point in the future.
I still like you, even if at some point you were reprogrammed to fear your imagination. =3
I assure you I am 100% turnip. =3
Failure to back up the assertion about "AI" existing in LLMs means there is no meaningful conversation to be had, but I offered to wait for a coherent argument in a time-bound manner. =3
> it's dangerous to look at the state of "AI" as it is today and then ignore the rate of change.
It's self driving all over again!
Self-driving cars are a social and political problem, not a technical one. If it were a technical problem, it would have been considered largely solved even in the pre-2017 era of ML.
Imagine a tramway train car that branched its rail-line at every intersection, person, animal, lane, or obstacle it detected.
1. What would that rail system look like?
2. How reliable would that service become after (6^(4+p+a+l)) per km branches?
3. Given #2, how much computing power is needed to evaluate that state always-mutating SLAM environment?
4. Ok... now throw out GPS (don't work in cities), Lidar (don't work in direct sunlight), and Machine vision cameras (fooled by weather and environment surfaces)...
5. Peoples wishful thinking tends to hijack common sense when someone else pays the price.
Easier to redefine what "autonomous vehicle" means with "levels", rather than to recognize how difficult the problem actually is inside an unconstrained system.
I would never claim to know anything about the subject, but I did help build working platforms when I was more interested in robotics for a time.
Making them "safe" is a whole different problem domain, =3
Case in point, under Case Study > Reconnaissance > OSINT, these two paragraphs follow one another - same content but different wording.
> The first step in any hardware hacking project is research. I started by Googling the router model number, "ASUS RT-N12 D1", and came across an article about a similar model, the ASUS RT-N12+ B1. The article mentioned that the device had an open UART interface allowing unauthenticated root access. However, it provided no exact details on how to exploit this or where the UART interface might be located. Could my router model have the same vulnerability?
> In the first step I googled the model number for my router "ASUS RT N12 D1" and I came accross this article. It shows that a similar model the "ASUS RT N12+ B1" appears to have an open UART interface, which gives unauthenticated root access. It does not show how to exacltly abuse this or any details where to find the UART interface. Let's see if our router model may have the same vulnerability!
Unfortunately not Open Source, in the common definition of the word.
From the license.md [0] page, under "Terms":
> Exemptions: Commercial Use: For inquiries regarding commercial use, please contact the author.
[0] https://github.com/f3nter/HardBreak/blob/fd3d2d4cd17624a3f62...
Thanks for your work in pointing this out! Like a trademark, we have to defend this term if we want its meaning to persist.
I don't have specific sources, but to those curious, the gist is this: open source, or more accurately free software or free culture, is not about the creator. It is about affirming the rights of the user, to use the work in any way they wish, which includes selling it.
A common phrase to correct this unfortunate misconception is "free as in speech, not as in beer". The price tag is not the issue (you can actually sell free work, like by commission or by phsyical copies), the freedom of the user is. This includes the freedom to reuse the content in a commercial manner. Just about the only freedom that may be restricted is the freedom to restrict others.
You may disagree with this, but this is just the history of the free software, free culture and open source movement, which built a significant portion of the software world we have today.
I just don't want anyone to copy the content and sell it. It's meant to be freely accessible to everyone.
That's fine. It's just not open source. Don't call it open source if it's not.
Definition: https://opensource.org/osd
Not everyone agrees with this definition. If the source is open to read, for me it's open source. The website you linked is an opinionated view on what open source is.
> If the source is open to read, for me it's open source
Not everyone agrees with the OSI definition but I'd say almost noone agrees with that definition there.
I think most people understand what you are describing as "Source Available". Could even be a commercial project.
> If the source is open to read, for me it's open source.
That’s called “source available”. Open source colloquially implies open license.
It's not. Open Source has its own definition.
You can define however you want, but it's not Open Source. What you mean is "source available".
I mean, there's not a lot we can do to stop you using the phrase in this way. But you should know that you will cause confusion. The phrase "open source" is, to an awful lot of people, a technical term with a specific meaning and has been so for decades now.
I think you misunderstand the debates happening around open source. They exist, but not for what you mean.
This reminds me of the discussion of whether if open source AI models are open source or not, when the training data is not available to the public.
I mean this lists MIT license as opensource license, when it's clearly not, because it doesn't at all mention source code. The license just talks about "software".
Anyone is free to publish only binaries+docs under this license, if they wish.
So the website is not very accurate.
[flagged]
that definition is wrong, really by just common sense
This is a shallow dismissal, which is against the HN Guidlines.
[flagged]
>Free and open-source software (FOSS) or free/libre and open-source software (FLOSS) is openly shared source code that is licensed without any restrictions on usage, modification, or distribution. Confusion persists about this definition because the "free", also known as "libre", refers to the freedom of the product, not the price, expense, cost, or charge. For example, "being free to speak" is not the same as "free beer".
I generally think of open source as where I can see the code and freely modify it, not necessarily freely commercialize it on my own.
I think I'm about where you are in all this, I see NC (restrictions that activities are non-commercial; like CC-NC) as being 'open source'.
Sure, I can't take your work, cut you off, then sell that work as if it were my own... but without explicit encouragement to do that (*), honour should inhibit that.
(* I'm aware some licenses give explicit encouragement to commercially exploit -- I just don't think that is the boundary for open source)
the FSF/OSI are big on emphasizing that "free/open" means more than exposing the designs and mechanisms; it means guaranteeing certain freedoms and rights to the users of your software.
what you're describing is usually called "source-available".
If open source doesn't specify a license that is it under then you should only assume that the source has been made available. Both GPL and Apache licensing are considered open source, even though apache is more permissive for commercial derivatives. No one calls GPL "source-available" in common conversation regardless of OSI's opinion.
As well as some variants of BSD licenses: https://en.wikipedia.org/wiki/BSD_licenses
>Two variants of the license, the New BSD License/Modified BSD License (3-clause), and the Simplified BSD License/FreeBSD License (2-clause) have been verified as GPL-compatible free software licenses by the Free Software Foundation, and have been vetted as open source licenses by the Open Source Initiative. The original, 4-clause BSD license has not been accepted as an open source license and, although the original is considered to be a free software license by the FSF, the FSF does not consider it to be compatible with the GPL due to the advertising clause.
Have you thought of a Creative Commons license? You can have a Non-Commercial clause, while letting others to cooperate with you and remix the information in your site. CC licenses are IMHO better suited for documents than things like GPL, BSD or MIT.
Note that the CC -ND licenses are not Open Source either.
That's a fair comment, maybe OP should change the Open Source part after all, even if the license is changed.
wrong. your definition essentially means "business friendly", the wiki is open source in every way that matters, except for "lets make money off this persons free work"
This is great timing. I recently purchased a micro:bit for learning with my young daughter (who loves it) and found I was very quickly out of my depth with even the most rudimentary customisation for the board.
My draws have now exploded with breadboards, alligator clips, jump wires, LCDs and various other electrical components and I'm in desperate need of understanding the fundamentals of how all these things work.
There's something magical and addictive about being able to control your own hardware components from your own code though. We've had great joy from simply lighting up LEDs and programming our IR receiver.
This is rad! I’ll throw this in my embedded resources round up [1]
Whoa! Very much appreciated!
Fantastic round-up with loads of useful inclusions. Thanks for sharing!
Nice! Hopefully it will grow to include circuit bending [1] techniques, those typically used for altering music machines and similar.
Just in case folks are curious, a circuit bending wiki does exist:
A minor nitpick, but it would be great if you put a description of the site in the meta/og description[0] so people get an explanation of what the site is when linking elsewhere, e.g. the same "This page is a free and open-source wiki about hardware hacking!" as is on the page itself. I just linked the site in Slack and it just says "hardbreak.wiki / Welcome to HardBreak | Hardbreak" which is pretty terse. I imagine there might be some setting in your wiki software that might populate these tags automatically (moreso than they already have), with any luck!
[0] https://ogp.me/
You are right! I encountered the same problem. Unfortunately, I didn't find a setting in Gitbook to change the preview text, just the preview image. It seems like it just takes the name of the first page 'Welcome to HardBreak' and adds the site name 'HardBreak' at the end. So I'd have to change the name of the first page, but a name like 'HardBreak - a Hardware Hacking Wiki' or something similar would look weird on the website, I think. I haven't found a good solution for that yet.
I think having it in the homepage title is fine. I do it for most sites I build for exactly this reason.
“HardBreak - Open-Source Hardware Hacking Wiki”
Looks fine as a title, and helps for embeds/sharing.
Shameless plug: For anybody wanting to get into rockchip SoC development I've created a (no AI) resource: https://danielc.dev/rk/
This is great.
I've always been on the application security side of things, but I'm increasingly interested in hardware hacking. Through some cursory research, I learned that there are a few scattered resources, but the best way to learn is to really work with someone who knows what they're doing.
Putting all these guides, roadmaps, etc. together in a single place is a great resource that I'll definitely use.
Thank you!
AI gen hogwash
Head to your local public library and pick any book pre 2020
hogwash because hogwash or because ai?
Instead of `strings` for the search[1], I recommend using `rz-bin`[2] and `rz-find`[3] tools, which offer more flexibility, searching strings outside of the data sections, searching for Unicode and less common encodings, and built-in cryptographic keys search. There are also `/` (search) commands in the Rizin itself. As for the entropy, there is a configurable and interactive histogram, see `p=` and `p==` commands, e.g. `p==e`.
[1] https://book.rizin.re/src/search_bytes/intro.html
Can anyone recommend a resource for how to (architecturally) handle communication with a device over i2c? That is where I am kinda stuck atm when it comes to programming a GPS device.
Backstory: at one point I was trying to use elixir/nerves on an rpi to manipulate a few sensor modules to try and produce a race lap timer for motorcycles: https://github.com/whalesalad/rabbit/blob/master/lib/rabbit/...
I bit off more than I could chew: learn elixir, learn i2c, and produce a novel library for controlling the ublox chip since nothing existed for Elixir.
But when it comes to managing the state of the device, reading/writing memory, etc.. that is all very foreign to me (I am used to sockets, http apis, etc) like request/response style interactions.
So it jumps into detail quickly and is written by a vendor but this is a pretty good guide handling the architecture and detail. See how read and writes use device and register addresses to issue requests, and responses are managed with clock pulses and bus arbitration.
thank you!
You might find some useful information on elinux.org here: https://elinux.org/Interfacing_with_I2C_Devices
Additionally, search on the wiki of i2c.
I know of one family that’s doing homeschooling. It’s not because of classmates, it’s because of curriculum failures. Their school district has messed up both reading (not doing phonics) and math. So if their kid goes to school they still have to go home and spend a lot of additional time learning. If they stay home, they learn everything they need in much less than a school day. This is only possible for them due to modern education software that lets them know exactly where their kid is at and where tutoring is needed.
This is good. I would've like to see the things that are possible by hacking hardware upfront. I think this help entice users by providing some exciting anticipation.
The wiki is free and open-source? Or the contents of the wiki are free and open-source?
If it's a wiki, it would be less than courteous to restrictively copyright public contributions (but I'm sure it's been done).
And presumably, paywalling it would reduce contributions.
My impression as to the number one barrier to hardware modifications is soldering. For some reason people can't or won't do it.
So I'd like to introduce the non-sponsor for this comment, "Pincel" the open firmware soldering iron
https://pine64.org/devices/pinecil/
It's running a risc-v chip on open firmware so you'll have cool points with when you whip it out at Richard Stallman's next BBQ.
It's nice that open firmware exists
but why on earth would a soldering iron need firmware to begin with?
Temperature control.
It can be done w/o software for sure, but it's easier to do PID with.
The Pinecil is great, but is definitely a terrible recommendation for anyone new to soldering. If you're trying to encourage people to learn to solder, they should be doing it with a proper station that can handle and maintain temp for extended periods. I have a Pinecil, but it's really only useful for quick on-the-fly jobs (which it excels at, in my experience) so it stays in my tool bag for work. It suffers from overheating and temperature changes for more lengthy jobs.
Otherwise, yeah, if you're already competent at soldering and need a pocket-sized iron that you can create a portable power supply for, invest in a Pinecil
Ok, next time I'll do it like this
<HUMOR> <!----- THIS IS THE FUNNY PART ----->
So I'd like to introduce the non-sponsor for this comment, "Pincel" the open firmware soldering iron
https://pine64.org/devices/pinecil/
It's running a risc-v chip on open firmware so you'll have cool points with when you whip it out at Richard Stallman's next BBQ.
<!-------- THE FUNNY PART IS ENDING HERE ------> </HUMOR>
So it's 10000000% clear I am making the joke.
Well, I feel stupid. Apologies!
One interesting feature: an index of all existing (already documented) hardware hacks on commercial devices. I know for example the IP camera industry has a large models that many different people are modding, but their docs are scattered all over github.
This is great, and sorely needed! My son wanted to get into hardware hacking a couple of years ago and had a horrible time. He ended up watching a mish-mash of varying quality youtube videos and reading blog posts which went out of date suprisingly quick.
Omg, wiki is recommending "Bus Pirate", this HW is many years old and basically abandoned project. Use something up-to-date, like Tigard and BitMagic.
Ian Lesnet/Dangerous Prototypes have within the last few months released the v5 Bus Pirate. Looks like he and the Dangerous Prototypes team might have taken on different ventures, but Ian has come back to the Bus Pirate.
On a personal note, I think the v5 hardware is pretty good, worth having alongside a Tigard since they are all so cheap anyway.
Edit: Apparently there's now a v5 XL and a v6 based on the RP2350 been released too, seems to be revived
Thanks this is an awesome resource! Especially to get into hardware hacking without getting lost in case studies... It looks super beginner friendly too
Great idea, and it's definitely an area I am becoming more interested in as a hobbyist.
Not to be that guy, but I always think it's a shame to see an open source community centre itself around a Discord server.
Thank you for your feedback! The Discord server serves as a platform for feedback and discussions about hardware hacking and HardBreak. Do you have any suggestions for alternative ways to offer these features?
I like IRC, but that seems to be an unpopular opinion these days (but maybe appropriate for a bunch of hardware hackers, since you could probably host it on an ESP32 if you were so inclined lol). There is also Matrix, which is somewhat more modern, or Zulip as another commenter has mentioned.
Ultimately it's your decision, and I guess Discord is probably easier to manage. Just consider that with Discord the discussions and knowledge that build up on the server don't really belong to you.
https://news.ycombinator.com/item?id=42685138 is the one I always post in any mention if Discord or Slack because they are both walled gardens
In your specific case, you may have to self-host or pay because I don't believe your project would qualify under their open source hosting offering but it wouldn't hurt to ask
I love it so much. I always wanted to get started with hardware hacking , and this is the right place to start !
Thanks for the wiki!
Thank you for the site.
I've been trying to learn how to customize Linux (e.g. roll my own Linux) for any platform but it takes time to learn since all the information is laid out all over the internet, thus hard to locate. I'm aware of Linux From Scratch project but it is a long read and I find that certain knowledge is assumed (e.g. why build chain is needed), thus not necessarily newbie-friendly. Though I've yet to go through your site, hopefully it will take the newbie inexperience (e.g. electronics knowledge if any) into consideration.
Good luck, SM68
Please remember to write "Show HN:" when submitting your own content.
I was thinking about it, but the Guidelines include this:
>Off topic: blog posts, sign-up pages, newsletters, lists, and other reading material. Those can't be tried out, so can't be Show HNs. Make a regular submission instead.
so I made a regular submission, as I think HardBreak is reading material. @Mods feel free to move my post, if this is considered a Show HN post.
I think you are right! I stand corrected.
whether partially open source or not, I appreciate this. Thanks, OP
Nice one, very user friendly.
Can't wait for the RFID section :)
fantastic providing such knowledge for free, many thanks
[dead]
Pos
_(cropped).jpg){kind=link}
{kind=link}