Hi HN, Francois here. Happy to answer any questions!
Here's a start --
"Did you get poached by Anthropic/etc": No, I am starting a new company with a friend. We will announce more about it in due time!
"Who uses Keras in production": Off the top of my head the current list includes Midjourney, YouTube, Waymo, Google across many products (even Ads started moving to Keras recently!), Netflix, Spotify, Snap, GrubHub, Square/Block, X/Twitter, and many non-tech companies like United, JPM, Orange, Walmart, etc. In total Keras has ~2M developers and powers ML at many companies big and small. This isn't all TF -- many of our users have started running Keras on JAX or PyTorch.
"Why did you decide to merge Keras into TensorFlow in 2019": I didn't! The decision was made in 2018 by the TF leads -- I was a L5 IC at the time and that was an L8 decision. The TF team was huge at the time, 50+ people, while Keras was just me and the open-source community. In retrospect I think Keras would have been better off as an independent multi-backend framework -- but that would have required me quitting Google back then. Making Keras multi-backend again in 2023 has been one of my favorite projects to work on, both from the engineering & architecture side of things but also because the product is truly great (also, I love JAX)!
Congrats, good luck with your new company!
I have one question regarding your ARC Prize competition: The current leader from the leaderboard (MindsAI) seems not to be following the original intention of the competition (fine tune a model with millions of tasks similar with the ARC tasks). IMO this is against the goal/intention of the competition, the goal being to find a novel way to get neural networks to generalize from a few samples. You can solve almost anything by brute-forcing it (fine tunning on millions of samples). If you agree with me, why is the MindsAI solution accepted?
> I was a L5 IC at the time
Kudos to Google for hiring extremely competent people, but I'm surprised that the creator and main architect of Keras hadn't been promoted to Staff Engineer at minimum.
Hierarchy aside, I am surprised the literal author and maintainer of the project, on Google’s payroll no less, was not consulted on such a decision. Seems borderline arrogant.
> ... was not consulted on such a decision ...
What Francois wrote suggests he was overruled.
Google being arrogant? Say it isn’t so!
Down leveling is a pretty common strategy larger companies use to retain engineers.
at certain levels in the corporate ladder, it's all about who or whom you glaze to get to that next level.
actual hard skills are irrelevant
It takes a while to get promoted, but he certainly did not leave as L5
Hello, Francois! My question isn't related directly to the big news, but to a lecture you gave recently https://www.youtube.com/watch?v=s7_NlkBwdj8&ab_channel=Machi... At 20:45 you say "So you cannot prepare in advance for ARC. You cannot just solve ARC by memorizing the solutions in advance." And at 24:45 "There's a chance that you could achieve this score by purely memorizing patterns and reciting them." Isn't that a contradiction? The way I understand it on one hand you are saying ARC can't be memorized on the other you are saying it can?
Hi Francois, I'm a huge fan of your work!
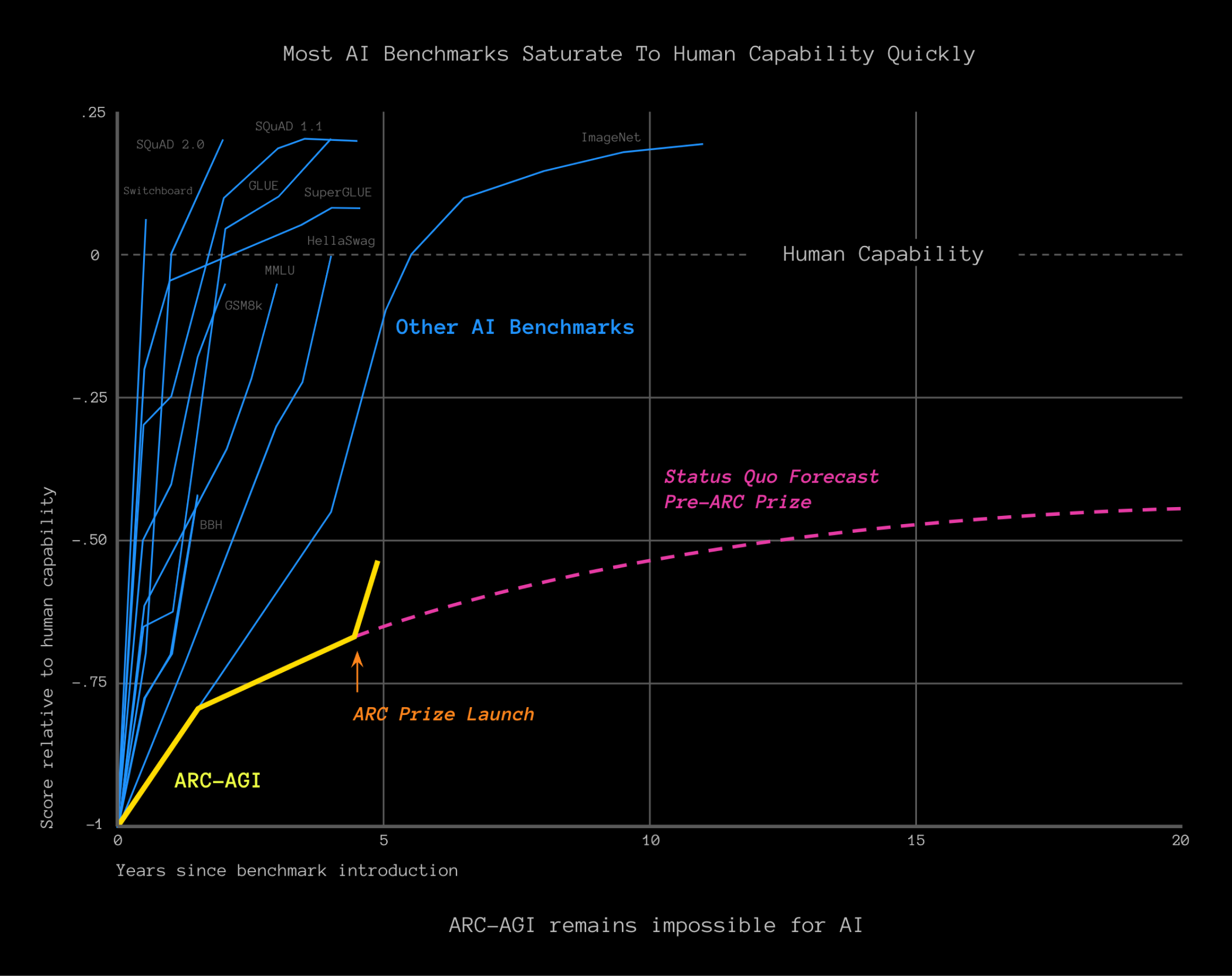
In projecting ARC challenge progress with a naive regression from the latest cycle of improvement (from 34% to 54%), it seems that a plausible estimate as to when the 85% target will be reached is sometime between late 2025 & mid 2026.
Supposing ARC challenge target is reached in the coming years, does this update your model of 'AI risk'? // Would this cause you to consider your article on 'The implausibility of intelligence explosion' to be outdated?
This roughly aligns with my timeline. ARC will be solved within a couple of years.
There is a distinction between solving ARC, creating AGI, and creating an AI that would represent an existential risk. ARC is a stepping stone towards AGI, so the first model that solves ARC should have taught us something fundamental about how to create truly general intelligence that can adapt to never-seen-before problem, but it will likely not itself be AGI (due to be specialized in the ARC format, for instance). Its architecture could likely be adapted into a genuine AGI, after a few iterations -- a system capable of solving novel scientific problems in any domain.
Even this would not clearly lead to "intelligence explosion". The points in my old article on intelligence explosion are still valid -- while AGI will lead to some level of recursive self-improvement (as do many other systems!) the available evidence just does not point to this loop triggering an exponential explosion (due to diminishing returns and the fact that "how intelligent one can be" has inherent limitations brought about by things outside of the AI agent itself). And intelligence on its own, without executive autonomy or embodiment, is just a tool in human hands, not a standalone threat. It can certainly present risks, like any other powerful technology, but it isn't a "new species" out to get us.
Congrats, François, and good luck!
Q: The ARC Prize blog mentions that you plan to make ARC harder for machines and easier for humans. I'm curious if it will be adapted to resist scaling the training dataset (Like what BARC did -- see my other comment here)? As it stands today, I feel like the easiest approach to solving it would be BARC x10 or so, rather than algorithmic inventions.
Right, one rather uninteresting line of approaches to ARC consists of trying to anticipate what might be in the test set, by generating millions of synthetic tasks. This can only work on relatively simple tasks, since the chance of task collision (between the test set and what you generate) is very low for any sophisticated task.
ARC 2 will improve on ARC 1 by making tasks less brute-forceable (both in the sense of making in harder to find the solution program by generating random programs built on a DSL, and in the sense of making it harder to guess the test tasks via brute force task generation). We'll keep the human facing difficulty roughly constant, which will be controlled via human testing.
Hi! As someone who spent the last month pouring myself into the ARC challenge (which has been lots of fun, thanks so much for creating it), I'm happy to see it made harder, but please make it harder by requiring more reasoning, not by requiring more human-like visual perception! ARC is almost perfect as a benchmark for analogical reasoning, except for the need for lots of image processing as well. [Edit: however, I've realised that perception is representation, so requiring it is a good thing.]
Any plan for more validation data to match the new harder testset?
I had never thought about how close perception and reasoning are from a computational point of view, the parts of ARC that we call "reasoning" seem to just be operations that the human brain is not predisposed to solve easily.
A very interesting corollary is that the first AGIs might be way better thinkers than humans by default because of how they can seamlessly integrate new programs into their cognition in a perfect symbiosis with computers.
I’m really going through it, trying to get legacy Theano and TensorFlow 1.x models from 2016 running on modern GPUs due to compatibility headaches due to OS, NVIDIA CUDA, CuDNN, drivers, docker, python, and package/image hubs all contributing their own roadblocks to actually coding. Ideally we would abandon this code, but we kind of need it running if we want to thoroughly understand our new model's performance on unseen old data, and/or understand Kappa scores between models. Will the move towards freeing Keras from TF again potentially reintroduce version chaos, or will it future proof it from that? Do you see a potential for something like this to once again befall tomorrow's legacy code relying on TF 1.x and 2.x?
Keras is now standalone and multi-backend again. Keras weights files from older versions are still loadable and Keras code from older versions are still runnable (on any backend as long as they only used Keras APIs)!
In general the ability to move across backends makes your code much longer-lived: you can take your Keras models with you (on a new backend) after something like TF or PyTorch stops development. Also, it reduces version compatibility issues, since tf.keras 2.n could only work with TF 2.n, but each Keras 3 version can work with a wide range of older and newer TF versions.
Hi François, just wanted to take the opportunity to tell you how much your work has been important for me. Both at the start, getting into deep learning (both keras and the book) and now with keras3 as I'm working to spread DL techniques in economics. The multi-backend is really a massive boon, as it also helps ensure that the API would remain both standardised and simple, which is very helpful to evangelise new users that are used to higher-level scripting languages as my crowd is.
In any case, I just want to say how much an inspiration the keras work has been and continues to be. Merci, François !
Thanks for the kind words -- glad Keras has been useful!
Thank you for Keras! Working with Tensorflow before Keras was so painful. When I first read the news I was just thinking you would make a great lead for the tools infra at a place like Anthropic, but working on your own thing is even more exciting. Good luck!
Congratulations Francois! Thanks for maintaining Keras for such a long time and overcoming the corporate politics to get it where it is now.
I've been using it since early 2016 and it has been present all my career. It is something I use as the definitive example of how to do things right in the Python ecosystem.
Obviously, all the best wishes for you and your friend in the new venture!!
Thank you!
> I was a L5 IC at the time and that was an L8 decision
omg, this sounds like the gigantic, ossified and crushing bureaucracy of a third world country.
It must be saying something profound about the human condition that such immense hierarchies are not just functioning but actually completely dominating the landscape.
I personally can't relate, but that's because I've never been in any organization at that scale, biggest companies I've been had employees numbering in the thousands, of which IT was only hundreds at most. There you go as far as having scrum teams with developers, alongside that one or more architect, and "above" that a CTO. Conversely, companies like Google have tens of thousands of people in IT alone.
But likewise, since we're fans of equality in my country, there's no emphasis on career ladders / progression; you're a developer, maybe a lead developer or architect, and then you get to management, with the only distinguishing factor being your years of experience, length of your CV, and pay grade. Pay grade is "simply" bumped up every year based on performance of both you personally and the company as a whole.
But that's n=1 experience, our own company is moving towards a career ladder system now as well. Not nearly as extensive as the big companies' though.
> > I was a L5 IC at the time and that was an L8 decision
> omg, this sounds like the gigantic, ossified and crushing bureaucracy of a third world country.
No, it sounds like how most successful organizations work.
Most large organizations are hugely bureucratic regardless of whether they are successful or not :-)
In any case the prompt for the thread is somebody mentioning their (subjective) view that the deep hiearachy they were operating under, made a "wrong call".
We'll never know if this true or not, but it points to the challenges for this type of organizational structure faces. Dynamics in remote layers floating somewhere "above your level" decide the fate of things. Aspects that may have little to do with any meritocracy, reasonableness, fairness etc. become the deciding factors...
> Aspects that may have little to do with any meritocracy, reasonableness, fairness etc. become the deciding factors...
If you're not presenting an alterative system, then is it still the best one you can think of?
There have been countless proposals for alternative systems. Last-in, first-out from memory is holacracy [1] "Holacracy is a method of decentralized management and organizational governance, which claims to distribute authority and decision-making through a holarchy of self-organizing teams rather than being vested in a management hierarchy".
Not sure there has been an opportunity to objectively test what are the pros and cons of all the possibilities. The mix of historical happenstance, vested interests, ideology, expedience, habit etc. that determines what is actually happening does not leave much room for observing alternatives.
Bureaucracy as per Weber is simply 'rationally organized action'. It dominates because this is the appropriate way to manage hundreds of thousands of people in a impersonal, rule based and meritocratic way. Third world countries work the other way around, they don't have professional bureaucracies, they only have clans and families.
It's not ossified but efficient. If a company like Google with about ~180.000 employees were to make decisions by everyone talking to everyone else you can try to do the math on what the complexity of that is.
Bureaucracies are certainly impersonal, but you'd be at a loss to find one that's genuinely rule based and meritocratic. To the extent that they become remain rule based they are no longer effective and get routed around. To the extent that they're meritocratic, the same thing happens with networks of influence. Once you get high enough, or decentralised enough bureaucracies work like any other human tribes. Bureaucracies may sometimes be effective ways to cut down on nepotism (although they manifestly fail at that in my country), but they're machines for manifesting cronyism.
> It's not ossified but efficient.
These are just assertions. Efficient compared to what?
> If a company like Google with about ~180.000 employees
Why should an organization even have 180000 employees? What determines the distribution of size of organizational units observed in an economy?
And given an organization's size, what determines the height of its "pyramid"?
The fact that management consultancies are making (in perpetuity) a plush living by helping reduce "middle management layers" tells you explicitly that the beast has a life of its own.
Empire building and vicious internal politics that are disconnected from any sense of "efficiency" are pretty much part of "professional bureaucracies" - just as they are of the public sector ones. And whether we are clients, users or citizens we pay the price.
>These are just assertions. Efficient compared to what?
Compared to numerous small companies of the aggregate same size. It's not just an assertion, Google (and other big companies) produces incredibly high rates of value per employee and goods at extremely low costs to consumers.
>Why should an organization even have 180000 employees? What determines the distribution of size of organizational units observed in an economy?
Coase told us the answer to this[1]. Organizations are going to be as large as they can possibly be until the internal cost of organization is larger than the external costs of transaction with other organizations. How large that is depends on the tools available to organize and the quality of organization, but tends larger over time because management techniques and information sharing tools become more sophisticated.
The reason why large organizations are efficient is obvious if you turn it on its head. If we were all single individual organizations billing each other invoices we'd have maximum transaction costs and overhead. Bureaucracy and hierarchies minimize this overhead by turning it into a dedicated disciplines and rationalize that process. A city of 5 million people, centrally administered produces more economic value than a thousand villages with the same aggregate population.
[1] https://onlinelibrary.wiley.com/doi/10.1111/j.1468-0335.1937...
Economic arguments almost always apply strictly to idealized worlds where each individual calculates the pennies for each action etc. The degree to which such deductions apply to the real world varies. In this case large bureaucracies are everywhere in the public sector as well, where, at least to first order, price mechanisms, profit maximization etc. are not the driving force. Hierarchy of some form is innate to human organization, this is not the point.
The alternative to a large organization with a sky-high hierarchy is not an inefficient solopreneur but a smaller organization with (possibly) a flater hierarchy. Even strictly within the Coase logic the "external cost" can be artificially low (non-priced externalities [1]), ranging from the mental health of employees, to the impact of oligopolistic markets on society's welfare etc. This creates an unusually generous buffer for "internal costs".
> In this case large bureaucracies are everywhere in the public sector as well, where, at least to first order, price mechanisms, profit maximization etc. are not the driving force.
I'd say that large bureaucracies are endemic to the public sector in large part because they can't use efficient price or profit mechanisms.
A firm doesn't typically operate like a market internally, but instead it operates like a command economy. Orders flow from the top to be implemented at lower levels, feedback goes the other way, and divisions should generally be more collaborative than competitive.
Bureaucracy manages that command economy, and some amount of it is inevitable. However, inevitability does not mean infallibility, and bureaucracies in general are prone to process orientation, empire-building, and status-based backstabbing.
> ranging from the mental health of employees
Nitpick: I think that disregard of employee mental health is bad, but I don't think it's an unpriced externality. Employees are aware of their own mental health and can factor it into their internal compensation/quality-of-life tradeoff, staying in the job only when the salary covers the stress.
I agree with all of that.
I think the main differences between private sector bureacracy and public sector bureaucracy are:
- I'm forced to fund the public sector bureaucracy
- There's no competitive pressure putting a lid on public sector bureaucracy
> Economic arguments almost always apply strictly to idealized worlds where each individual calculates the pennies for each action etc. The degree to which such deductions apply to the real world varies.
But the assumption that individuals actually make that calculation is not necessary for economic models to be useful.
For example, players who act in a game theoretically optimal way in some game will, over the long run, dominate and displace players who don't.
This is true even if those players don't actually know any game theory.
effective, maybe. efficient... I would not be so sure.
Depends on what you’re trying to achieve.
Small organizations define efficiency based on time to make number go up/down. Meanwhile, if something bad happens at 2am and no one wakes up - whatever there we’re likely no customers impacted.
Larger organizations are really efficient at ensuring the p10 (ie worst) hires are not able to cause any real damage. Every other thing about the org is set up to most cost effectively ensure least damage. Meanwhile, numbers should also go up is a secondary priority.
what does this comment even mean? how does an L8 telling an L5 to do something a reflection of a "gigantic, ossified and crushing bureaucracy of a third world country."? i can't figure out the salience of any of the 3 adjectives (nor third world).
> human condition that such immense hierarchies are not just functioning but actually completely dominating the landscape.
...how else do you propose to dominate a landscape? do you know of any landscapes (real or metaphorical) that are dominated by a single person? and what does this have to do with the human condition? you know that lots of other animals organize into hierarchies right?
if this comment weren't so short i'd swear it was written by chatgpt.
well others seems to be getting the meaning (whether they agree or not is another matter), so you might be too habituated to the "L" world to bother understanding?
> if this comment weren't so short i'd swear it was written by chatgpt.
ditto
Where's the evidence of it being ossified?
From one François to an other, thank you for you work, and all the best with your next endeavor!
Your various tutorials and your book "Deep Learning with Python" have been invaluable in helping me get up to speed in applied deep learning and in learning the ropes of a field I knew nothing about.
Hi Francois, congrats on leaving Google!
ARC and On the Measure of Intelligence have both had a phenomenal impact on my thinking and understanding of the overall field.
Do you think that working on ARC is one of the most high leverage ways an individual can hope to have impact on the broad scientific goal of AGI?
That's what I plan on doing -- so I would say yes :)
What are some AI frameworks you really like working with? Any that go overlooked by others?
My go-to DL stack is Keras 3 + JAX. W&B is a great tool as well. I think JAX is generally under-appreciated compared to how powerful it is.
Will you come back to Europe?
I will still be US-based for the time being. I'm seeing great things happening on the AI scene in Paris, though!
Hey,I really liked your little book of deep learning, even though I didn't understand everything in it yet. Thanks for writing it!
Er, isn't that by François Fleuret, not by François Chollet?
Enjoy the book!
just wanna take this chance to say a huge thank you for all the amazing work you’ve done with Keras!
back in 2017, Keras was my introductory framework to deep learning. it’s simple, Pythonic interface made finetuning models so much easier back then.
also glad to see Keras continue to thrive after getting merged into TF, especially with the new multi-backend support.
wishing you all the best in your new adventure!
Thanks for that, and thanks for Keras
Another happy Keras user here (under TF - but even before with Theano)
Hi Francois,
any chance to work or at least intern (remote, unpaid) with you directly? Would be super interesting and enriching.
> "Why did you decide to merge Keras into TensorFlow in 2019": I didn't! The decision was made in 2018 by the TF leads -- I was a L5 IC at the time and that was an L8 decision. The TF team was huge at the time, 50+ people, while Keras was just me and the open-source community. In retrospect I think Keras would have been better off as an independent multi-backend framework -- but that would have required me quitting Google back then.
The fact that an "L8" at Google ranks above an OSS maintainer of a super-popular library "L5" is incredibly interesting. How are these levels determined? Doesn't this represent a conflict of interest between the FOSS library and Google's own motivations? The maintainer having to pick between a great paycheck or control of the library (with the impending possibility of Google forking).
L8 at Google is not a random pecking order level. L8s generally have massive systems design experience and decades of software engineering experience at all levels of scale. They make decisions at Google which can have impacts on the workflows of 100s of engineers on products with 100millions/billions of users. There are less L8s than there are technical VPs (excluding all the random biz side VP roles)
L5 here designates that they were a tenured (but not designated Senior) software engineer. It doesn't meant they don't have a voice in these discussions (very likely an L8 reached out to learn more about the issue, the options, and ideally considered Francois's role and expertise before making a decision), it just means its above their pay grade.
I'll let Francois provide more detail on the exact situation.
This is just the standard Google ladder. Your initial level when you join is based on your past experience. Then you gain levels by going through the infamous promo process. L8 represents the level of Director.
Yes, there are conflicts of interests inherent to the fact that OSS maintainers are usually employed by big tech companies (since OSS itself doesn't make money). And it is often the case that big tech companies leverage their involvement in OSS development to further their own strategic interests and undermine their competitors, such as in the case of Meta, or to a lesser extent Google. But without the involvement of big tech companies, you would see a lot less open-source in the world. So you can view it as a trade off.
> How are these levels determined?
I have no knowledge of Google, but if L5 is the highest IC rank, then L8 will often be obtained through politics and playing the popularity game.
The U.S. corporate system is set up to humiliate and exploit real contributors. The demeaning term "IC" is a reflection of that. It is also applied when someone literally writes a whole application and the idle corporate masters stand by and take the credit.
Unfortunately, this is also how captured "open" source projects like Python work these days.
L5 isn't the highest IC level at Google. Broadly would go up to L10, but the ratio at every level is ~1:4 or 1:5 b/w IC levels.
The L7/L8 level engineers I've spoken or worked with have definitely earned it - they bring to bear significant large scale systems knowledge and bring it to bear on very large problem statements. Impact would be felt on billion$ impact wise.
The IC ladder at Google grows from L3 up to L10.
An L8 IC has similar responsibilities as a Director (roughly 100ish people) but rather than people, and priority responsibility it is systems, architecture, reliability responsibility.
I loved Keras at the beginning of my PhD, 2017. But it was just the wrong abstraction: too easy to start with, too difficult to create custom things (e.g., custom loss function).
I really tried to understand TensorFlow, I managed to make a for-loop in a week. Nested for-loop proved to be impossible.
PyTorch was just perfect out of the box. I don't think I would have finished my PhD in time if it wasn't for PyTorch.
I loved Keras. It was an important milestone, and it made me believe deep learning is feasible. It was just...not the final thing.
Keras 1.0 in 2016-2017 was much less flexible than Keras 3 is now! Keras is designed around the principle of "progressive disclosure of complexity": there are easy high-level workflows you can get started with, but you're always able to open up any component of the workflow and customize it with your own code.
For instance: you have the built-in `fit()` to train a model. But you can customize the training logic (while retaining access to all `fit()` features, like callbacks, step fusion, async logging and async prefetching, distribution) by writing your own `compute_loss()` method. And further, you can customize gradient handling by writing a custom `train_step()` method (this is low-level enough that you have to do it with backend APIs like `tf.GradientTape` or torch `backward()`). E.g. https://keras.io/guides/custom_train_step_in_torch/
Then, if you need even more control, you can just write your own training loop from scratch, etc. E.g. https://keras.io/guides/writing_a_custom_training_loop_in_ja...
> it was just the wrong abstraction: too easy to start with, too difficult to create custom things
Couldn’t agree with this more. I was working on custom RNN variants at the time, and for that, Keras was handcuffs. Even raw TensorFlow was better for that purpose (which in turn still felt a bit like handcuffs after PyTorch was released).
Keras was a miracle coming from writing stuff in Theano back in the day though.
Of course, it's easy to be ideological and defend technology A or B nowadays, but I agree 100% that in 2016/2016 Keras was the first touchpoint of several people and companies with Deep Learning.
The ecosystem, roughly speaking was: * Theano: Verbosity nightmare * Torch: Not-user friendly * Lasagne: A complex attraction on top of Theano. * Caffe: No flexibility at all, anything not the traditional architectures would be hard to implement * Tensor Flow: Unnecessarily complex API and no debuggability
I do not say that Keras solved all those things right away, but honestly, until just the fact that you could implement some Deep Learning architecture in 2017 on top of Keras I believe was one of the critical moments in Deep Learning history.
Of course today people have different preferences and I understand why PyTorch had its leap, but Keras was in my opinion the best piece of software back in the day to work with Deep Learning.
Wow that gives me flashbacks to learning Theano/Lasagne, which was a breath of fresh air coming from Caffe. Crazy how far we've come since then.
I didn't realize Keras was actually released before Tensorflow, huh. I used Theano quite a bit in 2014 and early 2015, but then went a couple years without any ML work. Compared to the modern libraries Theano is clunky, but it taught one a bit more about the models, heh.
And PyTorch was a miracle after coming from LuaTorch (or Torch7 iirc). We’ve made a lot of strides over the years.
Strange. Had never read blog posts about individual engineers leaving Google on official Google Developers Blog before. Is this a first? Every day someone prominent leaves Google... Sounds like a big self-own if Google starts to post this kind of stuff. Looks like sole post by either of the (both new to Google) authors in the byline.
Google is no longer the hot place to be. These blog posts are just soft launches of the engineers new companies. They're googlers, they know you gotta repeat yourself over and over to get mind share going :)
Same, what point does the post serve? And it's not like Keras is the hottest thing in DL world.
Even if it were, the article is written like a farewell email the employee sends to their group, not from Keras standpoint. I bet a couple rando VPs are writing self-promotional material to increase their visibility and they had nothing better to publish. Both are only 1yr in there. Google needs a DOGE (Department of Google Efficiency).
I guess they realized muilti-backend keras is futile? I never liked the tf.keras apis and the docs always promosed multi backend but then I guess they were never able to deliver that without breaking keras 3 changes. And even now.... "Keras 3 includes a brand new distribution API, the keras.distribution namespace, currently implemented for the JAX backend (coming soon to the TensorFlow and PyTorch backends)". I don't believe it. They are too different to reconcile under 1 api. And even if you could, I dont really see the benefit. Torch and Flax have similar goals to Keras and are imo better.
Multi-backend Keras was great the first time around and it might be a more widely used API today if the TF team hadn't pulled that support and folded Keras into TF. I'm sure they had their reasons but I suspect that decision directly increased the adoption of PyTorch.
Actually, `keras.distribution` is straightforward to implement in TF DTensor and with the experimental PyTorch SPMD API. We haven't done it yet first because these APIs are experimental (only JAX is mature) and second because all the demand for large-model distribution at Google was towards the JAX backend.
Why would you interpret this as Google disliking Keras? Seems a lot more likely he was poached by Anthropic.
Where did you see that he was poached by Anthropic?
I am not suggesting that I know it for a fact. I do recall some speculation on X to that effect but I can't find it now. Maybe just because Anthropic has been getting a lot of people lately.
If I were to speculate, I would guess he quit Google. 2 days ago, his $1+ million Artificial General Intelligence competition ended. Chollet is now judging the submissions and will announce the winners in a few weeks. The timing there can't be a coincidence.
More generally, there is unlimited opportunity in the AI space today, especially for someone of his stature, and staying tied to Google probably isn't as enticing. He can walk into any VC office and raise a hundred million dollars by the end of the day to build whatever he wants.
$100M isn't enough capital for an AI startup that's training foundation models, sadly.
A ton of folks of similar stature who raised that much burnt it within two years and took mediocre exits.
I think we'll start to see a differentiation soon. The likes of Ilya will raise money to do whatever, including foundation models / new arch, while other startups will focus on post-training, scaling inference, domain adaptation and so on.
I don't think the idea of general foundational model from scratch is a good path for startups anymore. We're already seeing specialised verticals (cursor, codeium, both at ~100-200m funding rounds) and they're both focused on specific domains, not generalist. There's probably enough "foundation" models out there to start working on post-training stuff already, no need to reinvent the wheel.
Chollet is a leading skeptic of the generality of LLMs (see arcprize.org). He surely isn't doing a startup to train another one.
Interesting, I think $100M is totally enough to train a SotA "foundation model". It's all in the use case. I'd love to hear explicit arguments against this.
There's a bunch of failed AI companies who raised been $100M and $200M with the goal of training foundation models. What they discovered is that they were rapidly out paced by the large players, and didn't have any way to generate revenue.
You're right that it's enough to train one, but IMO you're wrong that it's enough to build a company around.
can you please name names? I can't think of any (but am not an expert on the space).
I imagine Black Forest Labs (Flux) is doing alright, at least for now. I still feel like they’re missing out on some hanging fruit financially though.
But yeah, you’re not going to make any money making yet another LLM unless it’s somehow special.
Google, in my experience, is a place where smart people go to retire. I have many brilliant friends who work there, but all of them have essentially stopped producing interesting work since the day they started. They all seem happy and comfortable, but not ambitious.
I'm sure the pay is great, but it's not a place for smart people who are interested in doing something. I've followed Francois (and had the chance to correspond with him a bit) for many years now, and I wouldn't be surprised if the desire to create something became more important than the comfort of Google.
Am I almost alone in having no interest working for a large firm like Google?
I've been in tech since the 90s. The only reason I'd go is to network and build a team to do a mass exodus with and that's literally it.
I don't actually care about working on a product I have exactly zero executive control over.
tbh working at google has a lot of advantages that a lot of hackers don't appreciate until they start trying to doing their own thing.
For one thing as soon as you start doing your own thing you will quickly find your day eaten up by a trillion of small little admin (filling reports, chasing clients for payments, setting up a business address) things that you didn't know even exist. And that is not even taking into consideration the buisness development side of thing (going to marketing/sales meeting, arranging calls, finding product/market fit!, recruiting, setting up payroll....) At google you can have a career where 90% of the time you are basically just hacking.
Why zero executive control ? I’d expect a company like google ( like most large orgs ) to have a very large amount of internal code for internal clients, sometimes developer themselves. My experience of large orgs tells me you can have control over what you build - it depends on who you’re building it for ( external or internal)
That's not what I mean. I've got a deep interest in how a product is used, fits in a market, designed, experienced AND built.
If I went to Google what I'd really want to do is gather up a bunch of people, rent out an away-from-Google office space and build say "search-next" - the response to the onslaught of entries currently successfully storming Google's castle.
Do this completely detached and unmoored from Google's existing product suite so that nobody can even tell it's a Google product. They've been responding shockingly poorly and it's time to make a discontinuous step.
And frankly I'd be more likely to waltz upon a winning lottery ticket than convincing Google execs this is necessary (and it absolutely is).
I wonder how/if that mentality will shift over time. As it seems the market capture phase it over and the current big tech aren't simply keeping top talent around as a capture piece anymore.
Maybe they'll still do it, but basically only if it feels you can startup a billion dollar business. As opposed to a million dollar one.
Not really any different than what happened to IBM, Intel, Cisco, etc.
The people that want to build great things want the potential huge reward too, so they go to a startup to do it.
Except… it’s about leverage/impact factor. Google has very large impact, so if you do something big and central you’re instantly in the hands of hundreds of millions / billions of people. That’s a very different situation than IBM or Cisco.
you can say this about any Fortune 500 corporation, to be honest
It’s the other way around. Working at Google (or any other FAANG) for a time period past your personal “bullshit limit” will ensure you will never do anything ambitious with your life ever again.
ambitious? man, i can barely pay rent and i work at a FAANG.
Genuine question: who is using Keras in production nowadays? I've done a few work projects in Keras/TensorFlow over the years and it created a lot of technical debt and lost time debugging it, with said issues disappearing once I switched to PyTorch.
The training loop with Keras for simple model is indeed easier and faster than PyTorch oriented helpers (e.g. Lightning AI, Hugging Face accelerate) but much, much less flexible.
I implemented Keras in Production in 2019 (Computer Vision Classification for Fraud Detection) in my previous employer and I got in touch with the current team, they are happy and still using it in production with small updates only (security updates).
In our case, we made some ensembling with several small models using Keras. Our secret sauce at that time was in the specificity of our data and the labeling.
FTA "With over two million users, Keras has become a cornerstone of AI development, streamlining complex workflows and democratizing access to cutting-edge technology. It powers numerous applications at Google and across the world, from the Waymo autonomous cars, to your daily YouTube, Netflix, and Spotify recommendations."
sure -- all true in 2018; right about then pyTorch passed TensforFlow in the raw numbers of research papers using it.. grad students later make products and product decisions.. currently, pyTorch is far more popular, the bulk of that is with LLMs
source: pyTorch Foundation, news
The existence of a newer, hotter framework doesn't mean all legacy applications in the world instantly switch to it. Quite the opposite in fact.
We run a decent Keras model on production.
I don’t need a custom loss function, so keras is just fine.
From the article it sounds like Waymo run on Keras. Last I checked Waymo was doing better than the PyTorch powered Uber effort.
As someone who hasn't really used either, what's pytorch doing that's so much better?
A few things from personal experience:
- LLM support with PyTorch is better (both at a tooling level and CUDA level). Hugging Face transformers does have support for both TensorFlow and PyTorch variants of LLMs but...
- Almost all new LLMs are in PyTorch first and may or may not be ported to TensorFlow. This most notably includes embeddings models which are the most important area in my work.
- Keras's training loop assumes you can fit all the data in memory and that the data is fully preprocessed, which in the world of LLMs and big data is infeasible. PyTorch has a DataLoader which can handle CPU/GPU data movement and processing.
- PyTorch has better implementations for modern ML training improvments such as fp16, multi-GPU support, better native learning rate schedulers, etc. PyTorch can also override the training loop for very specific implementations (e.g. custom loss functions). Implementing them in TensorFlow/Keras is a buggy pain.
- PyTorch was faster to train than TensorFlow models using the same hardware and model architecture.
- Keras's serialization for model deployment is a pain in the butt (e.g. SavedModels) while PyTorch both has better implementations with torch.jit, and also native ONNX export.
I think a lot of these may have improved since your last experience with Keras. It's pretty easy to override the training loop and/or make custom loss. The below is for overriding training / test step altogether, custom loss is easier by making a new loss function/class.
https://keras.io/examples/keras_recipes/trainer_pattern/
> - Keras's training loop assumes you can fit all the data in memory and that the data is fully preprocessed, which in the world of LLMs and big data is infeasible.
The Tensorflow backend has the excellent tf.data.Dataset API, which allows for out of core data and processing in a streaming way.
That's a fair implementation of custom loss. Hugging Face's Trainer with transformers suggests a similar implementation, although their's has less boilerplate.
https://huggingface.co/docs/transformers/main/en/trainer#cus...
PyTorch is just much more flexible. Implementing a custom loss function, for example, is straightforward in PyTorch and a hassle in Keras (or was last time I used it, which was several years ago).
Being successful is also why it's better. PyTorch has a thriving ecosystem of software around it and a large userbase. Picking it comes with many network benefits.
His tweets are quite interesting. E.g.
https://x.com/fchollet/status/1638057646602489856
Very insightful to have a number from him here:
> LLMs are trained on much more than the whole Internet -- they also consume handcrafted answers produced by armies of highly qualified data annotators (often domain experts). Today approximately 20,000 people are employed full-time to produce training data for LLMs.
I read somewhere TF will not be developed actively down the road, Google switched to JAX internally and TF pretty much lost the war to Pytorch.
Jax is really nice
Is PyTorch genuinely so good that most people have stopped using Keras/TF?
I've always wondered how fchollet had authority to force keras into TF...
I remember this post as the day that Keras died. Very strange political powerplay on the part of fchollet, and did immeasurable damage to the community and code that used TF, not just in that PR but also in the precedent it set for other stuff. People legitimately were upset by the attempt to move tensorflow under an unnecessary Keras namespace, and he locked the PR and said that Reddit was brigading it (despite it being pretty consistently disliked as a change, among other changes). People tried to reason with him in the PR thread, but to no avail, the Keras name had to live on, whether or not TF died with it (and it very well did, unfortunately). There were other things working against TF but this one seemed to be the final nail in the coffin, from what I can tell.
I ended up minimizing engagement with the work he's done since as a result.
notably that link shows “@tensorflow tensorflow deleted a comment from fchollet on Nov 21, 2018” as well as other deleted comments
Hello François, thank you for your great work to the Open Source community. Aren't you worried that your work may only be profitable to some US-based interests that may backfire to your home country ? given the actual political situation... France needs you, come back home. This is not a judgment, just wondering about your opinion on it.
I wonder what he will be working on?
Maybe he figured out a model that beats ARC-AGI by 85%?
> Maybe he figured out a model that beats ARC-AGI by 85%?
People have, I think.
One of the published approaches (BARC) uses GPT-4o to generate a lot more training data.
The approach is scaling really well so far [1], and whether you expect linear scaling or exponential one [2], the 85% threshold can be reached, using the "transduction" model alone, after generating under 2 million tasks ($20K in OpenAI credits).
Perhaps for 2025, the organizers will redesign ARC-AGI to be more resistant to this sort of approach, somehow.
---
[1] https://www.kaggle.com/competitions/arc-prize-2024/discussio...
[2] If you are "throwing darts at a board", you get exponential scaling (the probability of not hitting bullseye at least once reduces exponentially with the number of throws). If you deliberately design your synthetic dataset to be non-redundant, you might get something akin to linear scaling (until you hit perfect accuracy, of course).
I like the idea of ARC-AGI and think it was worth a shot. But if someone has already hit the human-level threshold, I think the entire idea can be thrown out.
If the ARC-AGI challenge did not actually follow their expected graph[1], I see no reason to believe that any benchmark can be designed in a way where it cannot be gamed. Rather, it seems that the existing SOTA models just weren't well-optimized for that one task.
The only way to measure "AGI" is in however you define the "G". If your model can only do one thing, it is not AGI and doesn't really indicate you are closer, even if you very carefully designed your challenge.
> But if someone has already hit the human-level threshold
There is some controversy over what the human-level threshold is. A recent and very extensive study measured just 60.2% using Amazon Mechanical Turkers, for the same setup [1].
But the Turkers had no prior experience with the dataset, and were only given 5 tasks each.
Regardless, I believe ARC-AGI should aim for a higher threshold than what average humans achieve, because the ultimate goal of AGI is to supplement or replace high-IQ experts (who tend to do very well on ARC)
---
[1] Table 1 in https://arxiv.org/abs/2409.01374 2-shot Evaluation Set
It is scientific malpractice to use Mechanical Turk to establish a human-level baseline for cognitively-demanding tasks, even if you ignore the issue of people outsourcing tasks to ChatGPT. The pay is abysmal and if it seems like the task is purely academic and hence part of a study, there is almost no incentive to put in effort: researchers won't deny payment for a bad answer. Since you get paid either way, there is a strong incentive to quickly give up thinking about a tricky ARC problem and simply guess a solution. (IQ tests in general have this problem: cynicism and laziness are indistinguishable from actual mistakes.)
Note that across all MTurk workers, 790/800 of evaluation tasks were successfully completed. I think 98% is actually a better number for human performance than 60%, as a proxy for "how well would a single human of above-average intelligence perform if they put maximal effort into each question?" It is an overestimate, but 60% is a vast underestimate.
> The only way to measure "AGI" is in however you define the "G"
"I" isn't usefully defined either.
At least most people agree on "Artificial"
That's the problem with intelligence vs the other things we're doing with deep learning.
Vision models, image models, video models, audio models? Solved. We've understood the physics of optics and audio for over half a century. We've had ray tracers for forever. It's all well understood, and now we're teaching models to understand it.
Intelligence? We can't even describe our own.
What you're calling "gamed" could actually be research and progress in general problem solving.
Almost by definition it is not. If you are "gaming" a specific benchmark, what you have is not progress in general intelligence. The entire premise of the ARC-AGI challenge was that general problem solving would be required. As noted by the GP, one of the top contenders is BARC which performs well by generating a huge amount of training data for this particular problem. That's not general intelligence, that's gaming.
There is no reason to believe that technique would not work for any particular problem. After all, this problem was the best attempt the (very intelligent) challenge designers could come up with, as evidenced by putting $1m on the line.
> That's not general intelligence, that's gaming.
In fairness, their approach is non-trivial. Simply asking GPT-4o to fantasize more examples wouldn't have worked very well. Instead, they have it fantasize inputs and programs, and then run the programs on the inputs to compute the outputs.
I think it's a great contribution (although I'm surprised they didn't try making an even bigger dataset -- perhaps they ran out of time or funding)
> If you are "throwing darts at a board", you get exponential scaling (the probability of not hitting bullseye reduces exponentially with the number of throws).
Honest question - is that so, and why? I thought you have to calculate the probability of each throw individually as nothing fundamentally connects the throws together, only that long term there will be a normal distribution of randomness.
> The probability of not hitting bullseye at least once ...
I added a clarification.
I personally think ARC-AGI will be a forgotten, unimportant benchmark that doesn't indicate anything more than a models ability reason, which honestly is just a very small step in the path towards AGI
My interest was piqued, but the extrapolation in [1] is uh... not the most convincing. If there were more data points then sure, maybe
The plot was just showing where the solid lines were trending (see prior messages), and that happened to predict the performance at 400k samples (red dot) very well.
An exponential scaling curve would steer a bit more to the right, but it would still cross the 85% mark before 2000k.
ARC is a bigger contribution than Keras. It’s great he had two major contributions. I can’t wait to see how they crack ARC
Do you plan to write more "fundamental" AI papers such as "On the measure of intelligence", do you plan to refine your ARC-AGI benchmark again?
Yes to both.
Francois good luck with your new beginning. Your book (and aurelien one) greatly helped me entering this field
{kind=link}